Japanese-Car-Price-Predictions
Car Price Predictions Using Supervised Learning Models
About
A Japanese car company that has recently attempted to launch vehicles in the US market. During this attempt, sales were low as an initial analysis resulted in overpriced vehicles. Initial price estimates were based on previous experience setting prices in the Japanese market by executives within Akashi. This process relied heavily on intuition and assumptions, like factors influencing prices in Japan would being the same in the US.
Akashi’s management team has hired me as a consultant to build a regression model based on a dataset of cars they plan to sell into the American market. Their hope is that they will be able to use this model to predict the most appropriate price for the cars they will sell in the American market.
Skills Showcased
- Supervised Machine Learning - Decision Trees, K-Nearest Neighbour, SVR
- Data Cleaning
- Feature Engineering
- Data Analysis
Libraries Overview
The following Python libraries will be used for this project.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn.linear_model as skl
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
Preparing the Data
Before applying the regression models the dataset needs to be prepared. First, we will define our x/predictors and y/response variables.
# Assigning the 'price' column to the 'response' variable
response = car_prices_us[['price']]
# Assigning all of the columns except 'price' to the 'predictors' variable
predictors = car_prices_us.drop(['price'], axis=1)
Irrelevant Data
We must then look at removing features that measure the same or similar metrics, for example, we can drop "carwidth" and "carheight" and keep "carlength". We can also remove some features that we know will not impact the asking price of the vehicle.
# Selecting numeric predictors for correlation analysis
numeric_columns = car_prices_us.iloc[:,10:]
numeric_columns = numeric_columns.drop(["compressionratio", "stroke", "symboling", "peakrpm",
"horsepower", "carlength", "citympg", "carheight"],
axis=1)
With these removed, we can check which of the remaining features have a high correlation with one another. Using a correlation matrix and plotting it with a heatmap we can see that all of the remaining features are okay to keep. We can now drop the features we found to be irrelevant from our "predictors" variable at this point.
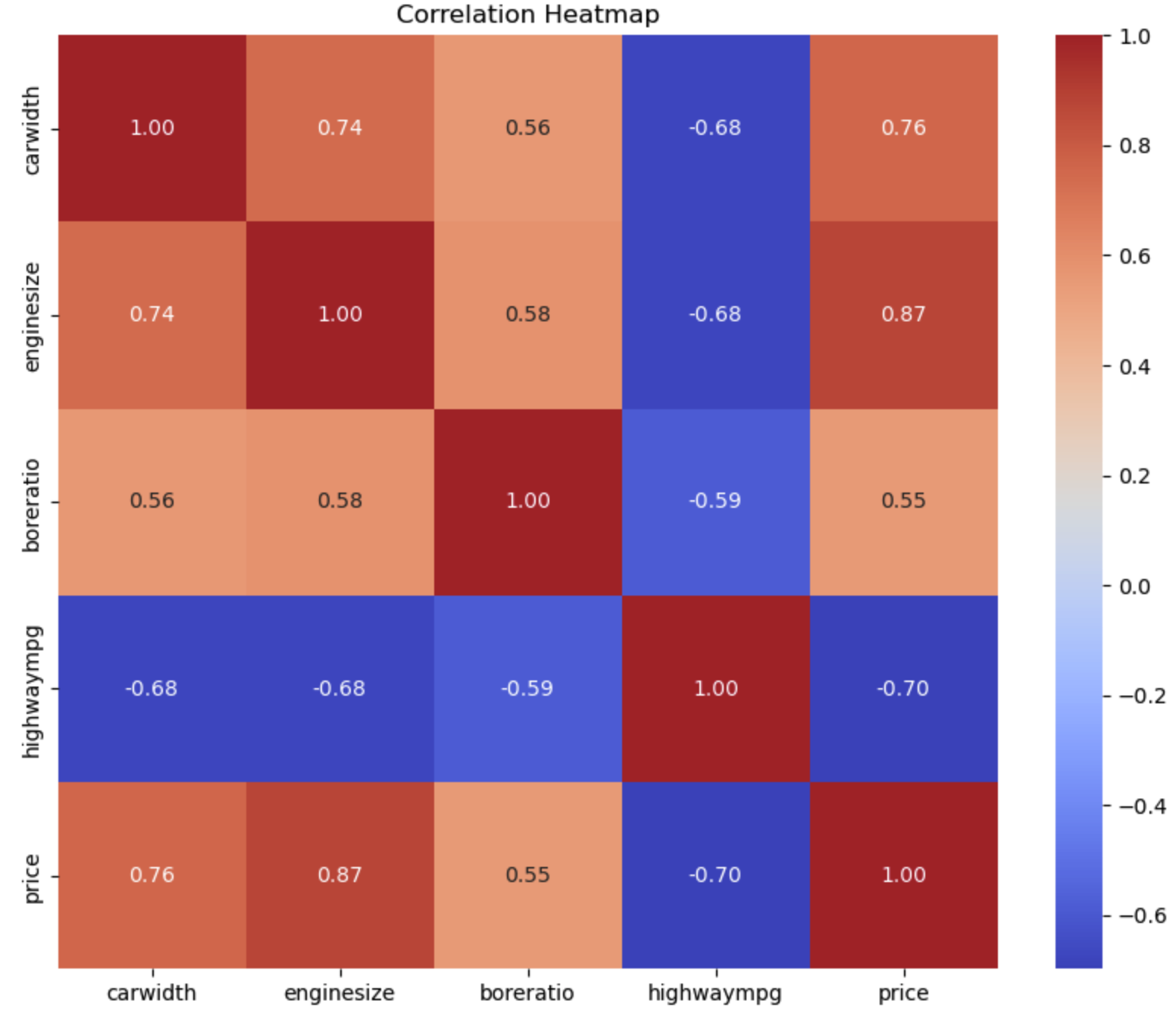
# Removing predictors that have a correlation above 0.8 and below 0.2 and updating variable
predictors = predictors.drop(["compressionratio", "stroke", "symboling", "peakrpm",
"horsepower", "carlength", "citympg", "carwidth", "carheight"],
axis=1)
Categorical Data
The linear regression models cannot deal with non-numeric data, as a work around for this we will convert categorical data to numeric. In this case, we will use the one-hot encoding method, which will convert each categorical column into two binary columns, one true and one false.
predictors = pd.get_dummies(predictors,drop_first=True)
Creating the Models
Linear Regression
Having prepared the data we can begin to create models. The first model we will create is a linear regression model. After we fit the model to our data we will measure the accuracy using R Squared and adjusted R Squared.


As we can see above the model is highly accurate, now we have to check if the model fits the assumptions of linear regression:
- The data is normally distributed.
- The data is evenly distributed.
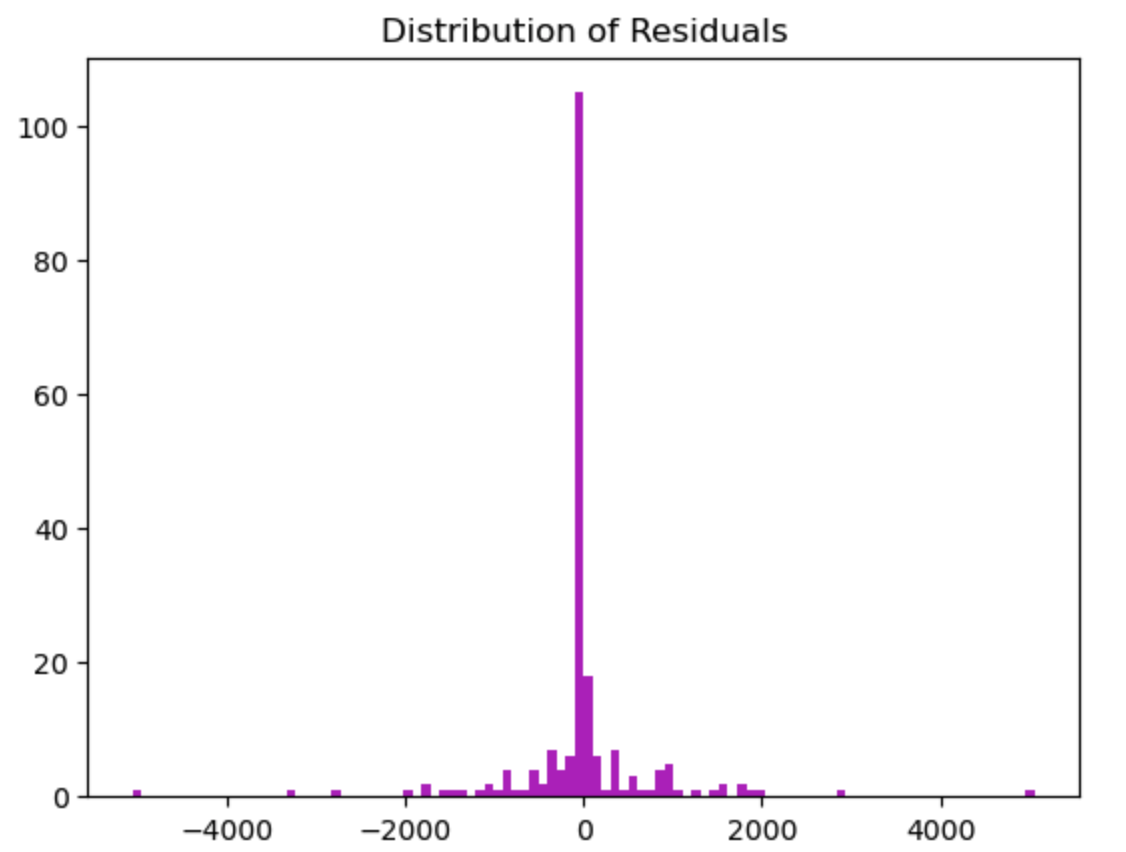
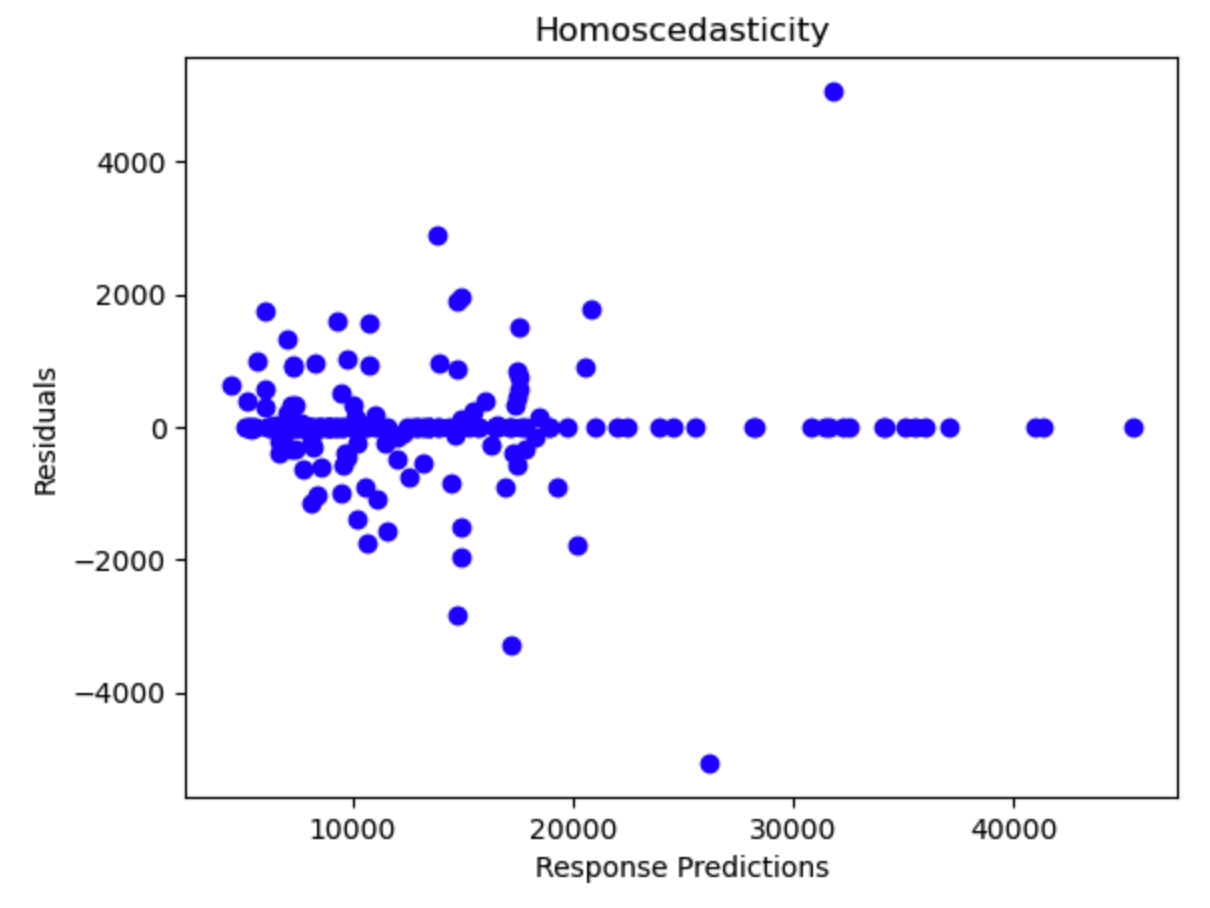
As per the above plots, we can see that the data is normally distributed, however, the model was far more likely to provide inaccurate predictions for cheaper cars than for expensive ones. So this model must be rejected.
Non-Parametric Models
These models will be less accurate than linear regression but they can violate assumptions and still be acceptable to use. We will use three different models to see which proves to be the most accurate.
To begin using these types of models we will need to split our data into training and testing sets, this will help us test the accuracy of our model’s predictions.
predictors_train, predictors_test, response_train, response_test = train_test_split(
predictors, response, test_size=0.2, random_state=42)
Decision Trees

K Nearest Neighbours

Support Vector Regression

We can see from the above scores that the KNN model provides us with the most accurate predictions of car prices. For this reason, we will propose that the firm implement our K Nearest Neighbours algorithm to most accurately predict car prices for the American market.